

3 common data test mistakes when evaluating an AML vendor
Written by Elena Dulskyte
Written by Elena Dulskyte
Welcome to the era of artificial intelligence (AI) hype, where every company and its cat claims to be riding the wave of the latest AI and machine learning (ML) breakthroughs. One example of this in the anti-money laundering (AML) space is the buzz around the newest large language models (LLM). Such AI-powered systems pledge to revolutionize compliance teams’ efficiency, alleviating the burden of repetitive tasks.
But how do firms discern reality from exaggeration? And when the AI models get increasingly complex, will they do what they are told?
Data tests have become an industry standard to verify the performance of complex AML screening products.
A data test is a systematic evaluation of data sets and algorithms to assess their quality, accuracy, and reliability. They are a practice run for a screening provider in their most basic form, with many examples being tested. They typically involve applying predefined criteria or algorithms to identify anomalies, errors, or inconsistencies within the data.
While data tests serve as the bedrock of sound analysis, common pitfalls often emerge. This article scrutinizes three of the most common missteps in the data testing process and provides insights into effective remediation strategies.
For compliance screening providers, two objectives reign supreme:
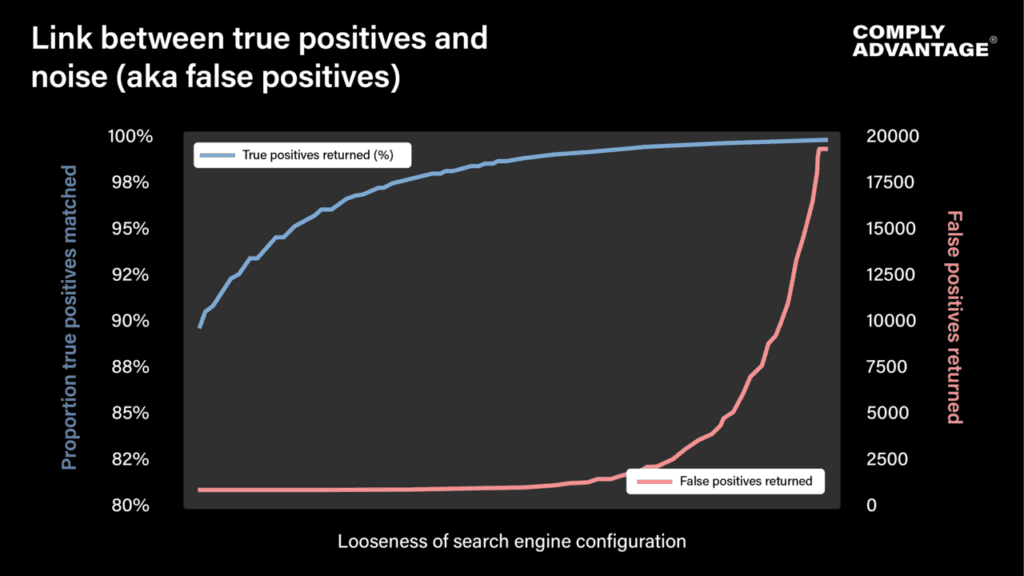
Surprisingly, many data tests overlook the interconnectedness of true and false positives, failing to acknowledge the tradeoff between them.
When this crucial link is missed, an inefficient loop is created where a data test result recommends the loosest engine settings, causing compliance processes to crumble under an unrealistic workload a few weeks later.
The fix: When designing a data test, include both true positive searches and false positive searches. Whenever possible, make false positives plentiful and representative of real-life searches.
Pro-tip: Don’t tell potential screening vendors which searches are supposed to generate hits.
Data tests can assess a plethora of use cases. However, not all tests apply to every use case. An ideal data test would be designed with a firm’s data pipeline and customer demographics in mind.
When considering a plausible case of corruption, for example, firms should consider the following:
The fix: Carefully consider the data pipeline when designing tests. If there are any known historic true hits, test them too.
Despite various tests to detect the deliberate use of homoglyphs (aka search engine gaming) and mirror image tests (where names are spelled back-to-front), some major compliance pain points remain unaddressed.
Imagine a new valuable customer named “Mohamad Ahmad” needs to be onboarded.
There are ~150 million people in the world named Mohamad. And about one in 25 of them has the surname Ahmad. A back-of-the-envelope estimation says there should be about six million people with this name, and a few dozen of those six million people will be sanctioned, while others will have other AML risks attached.
With a basic search engine, investigating all potential risks associated with “Mohamad Ahmad” could take days. Even then, the investigation is likely to be flawed due to the sheer volume of manual work involved. Without additional supporting information, risks associated with individuals like Mohamad Ahmad remain virtually unfindable.
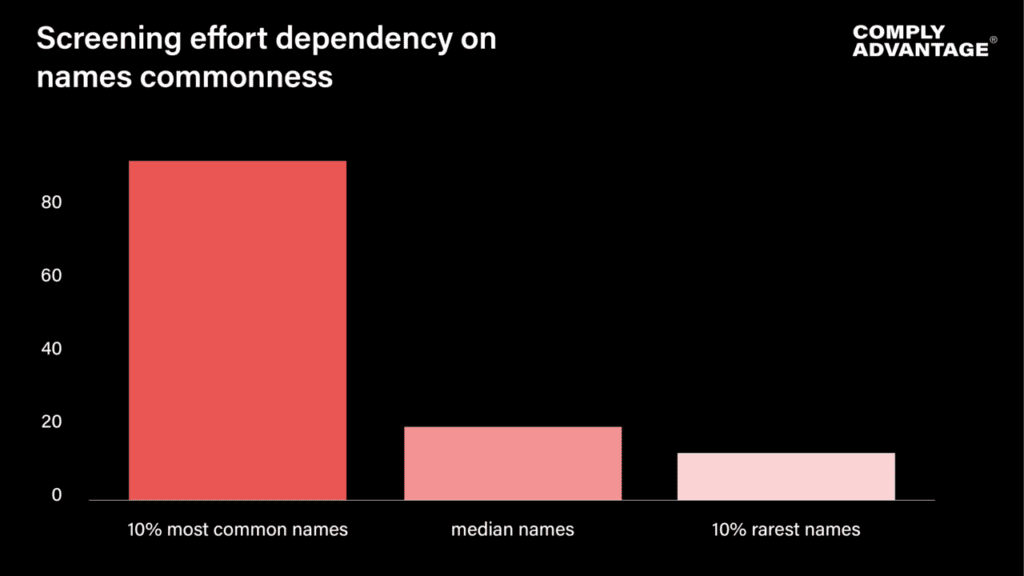
While a relatively small proportion of names (up to 10 percent) are extremely common, they are responsible for many remediation efforts. Hence, most data tests underplay the importance of this compliance pain point.
The fix: Add supporting information that helps narrow down the search. Mohamad Ahmad, born in 1990 and living in the UK, should be a much easier case to screen when all data is used effectively. For data tests, add common names and supporting information to test these cases.
As more AI-powered screening solutions enter the market, rigorous testing will be the cornerstone of informed decision-making. By scrutinizing screening providers through comprehensive data tests and addressing common pitfalls, businesses can harness the full potential of AI while mitigating compliance risks and maximizing operational efficiency.
Streamline compliance and mitigate risk effectively with ComplyAdvantage’s industry-leading solutions. Speak with one of our experts today.
Request a demoOriginally published 11 March 2024, updated 04 February 2025
Disclaimer: This is for general information only. The information presented does not constitute legal advice. ComplyAdvantage accepts no responsibility for any information contained herein and disclaims and excludes any liability in respect of the contents or for action taken based on this information.
Copyright © 2026 IVXS UK Limited (trading as ComplyAdvantage).