
Explore the power of AI-driven adverse media
Analyze negative news at scale with our robust screening software.
Find out moreData is made up of qualitative and quantitative information updated every second of every day worldwide. But as data streams increase in size and complexity, the speed at which financial institutions utilize these insights, and the need to ensure that the insights themselves are relevant, has become just as vital as the insights themselves.
Many data collection methods are available. The most common are human-led, such as keyword searches using search engines. However, these manual approaches are not sufficient when trying to cover, for example, versions of the same words with minimal context.
The most effective methods use artificial intelligence (AI), and there are multiple reasons it is essential for data collection.
Collecting and reviewing data across adverse media, sanctions, politically exposed persons (PEPs), and relatives and close associates (RCAs) can be difficult and time-consuming. Depending entirely on people for operational efficiency can increase the risk of false positives, especially when organizations rely on manpower to input information and achieve results.
Data collection with AI and machine learning tools is an alternative way to gather the information organizations need in an automated way effectively – ensuring business continuity during times of uncertainty.
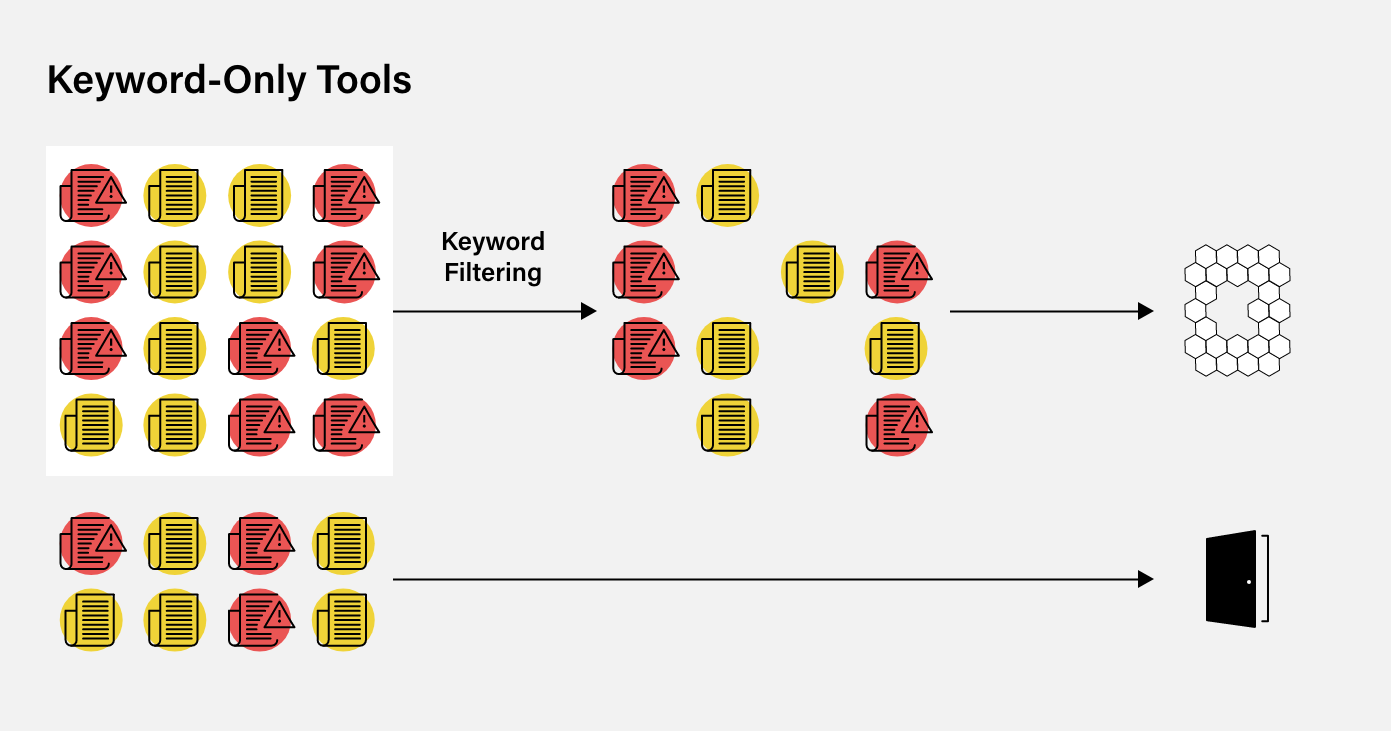
It can be challenging to visualize why keywords are ineffective on their own. When onboarding clients, compliance professionals need to refer to an adverse media database that has no glaring errors or gaps.
Suppose a simple system is used that only processes keyword filtering. In this case, just a select number of media sources can be captured and analyzed, which doesn’t necessarily provide the whole picture. Since only the sources containing the keywords will be flagged, some will inevitably slip through the net.
In turn, this can create a high number of false-positive results, which have to be filtered manually, costing already overstretched compliance teams additional time and resources.
Furthermore, compliance staff won’t be able to detect the adverse media that isn’t included in the select number of media sources. They won’t even know that it exists. In this case, a door has essentially been left open for those entities to enter the business.
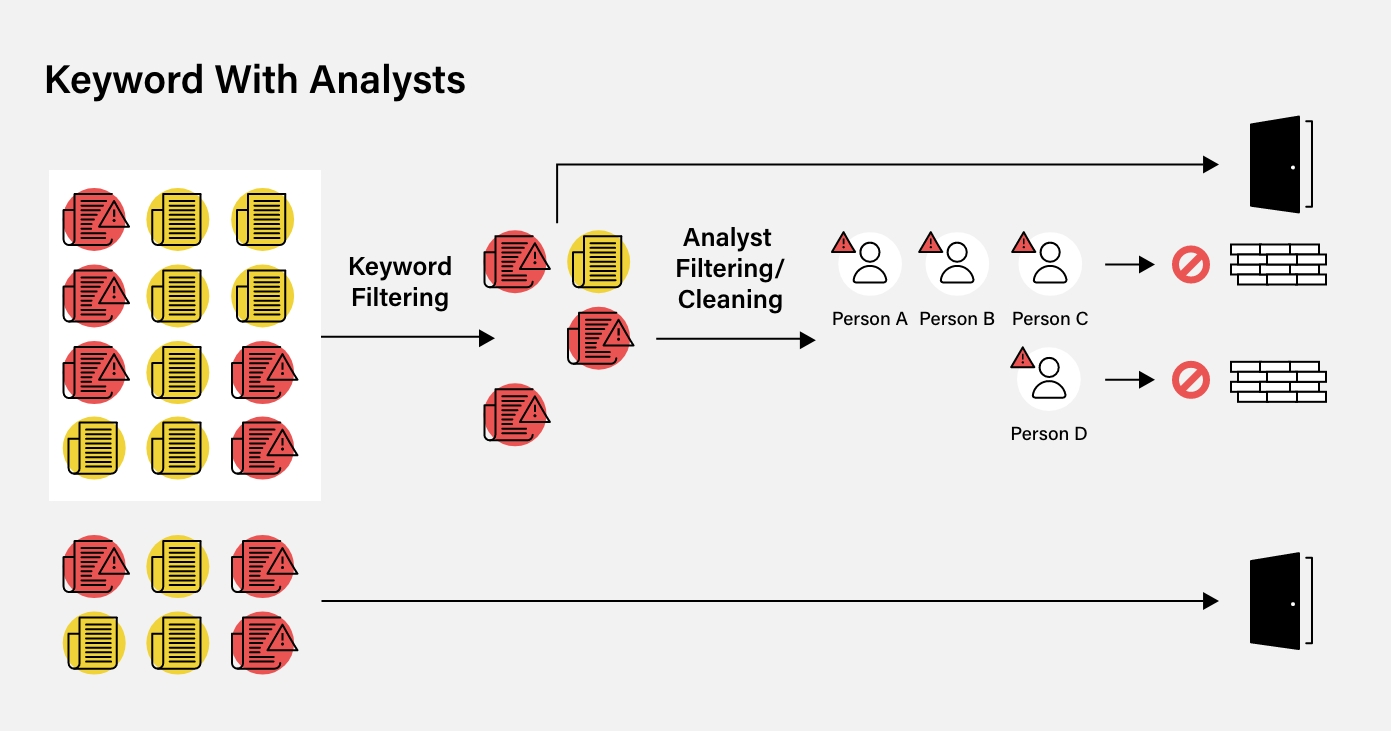
Alongside using keyword searches, analysts can manually filter and check data. Analysts can take information at the “chainlink fence stage” and filter data. Unfortunately, this approach also has its limitations.
Analysts manually input and produce the results, meaning data cannot be updated in real-time and can also include their own biases when filtering through onboarding profiles. They may miscategorize some articles as adverse (or not), and those negatively impacted by being wrongly labeled may now face ongoing financial issues.

Machine learning and natural language processing-based solutions are superior. Using machine learning to create an adverse media database and filter entities effectively minimizes human error. The limit here is the amount of media produced on any given day by media sources. There is no need to select just a portion of media to examine. All of it is available to be reviewed.
Reducing human interruption at this stage also means that adverse media can be identified constantly and without time limits, irrespective of external factors.
Once the adverse media is identified, the information is extracted and assigned to profiles matching real-world entities without creating duplicates. Then, when entities with negative news articles attempt to onboard a business, compliance teams can quickly identify and reject them as necessary.
For many reasons, taking advantage of machine learning and natural language processing is necessary. It creates an effective adverse media database by examining all the data available. It constantly works, identifying the data that matters and presenting it in a format that is easily accessible. It is here that it can also be used in conjunction with advanced name-matching and person-identifying systems.
Machine learning provides entity profiles that can be used to rapidly decide whether or not to onboard a customer according to the risk appetite of the individual business. Without using machine learning-based solutions, companies will never be able to identify all of the potential customers who pose a threat to compliance obligations.
But, machine learning tools are not just useful for adverse media products. Sanctions and PEP information also change regularly, and businesses must ensure that their data is up to date to avoid a breach or making overly risky decisions.
Sanctions data is always changing, but new heights were reached in 2022 following Russia’s invasion of Ukraine. At this time, the most comprehensive sanctions were imposed against a major power since the end of the Second World War, with the US, European Union (EU), and others coordinating their actions in new ways.
As we have seen, sanctions lists can be changed without short notice, and amendments can be similarly chaotic in delivery. In our survey, 96 percent of firms told us real-time AML risk data would improve their response to sudden sanctions regime changes, like those that followed the invasion. As such, a unified structure on how sanctioned data is delivered to businesses is critical to ensure firms do not begin or continue a relationship with a sanctioned entity.
ComplyAdvantage’s adverse media product leverages AI for contextual understanding and a manual review process – thus creating a highly accurate data set, updated automatically on an ongoing basis at unprecedented speed. A firm’s workload can be reduced by having both reviewal methods working together.
PEPs constantly change positions, and new players enter the field. Data collection tends to move as fast as politics and frequently needs updating. Critical PEP coverage is vital to every financial service business. Using machine learning, firms can obtain information on all 245 countries and jurisdictions for essential class 1 PEP across the executive, legislative, and judiciary branches.
According to our survey data, compliance professionals are increasingly seeking the ability to track changes in PEP positions, particularly regarding mid-level officials. When asked which area their firm most valued in a PEP screening solution, 39 percent said mid-level government officials, a ten percentage point increase on 2021 that made it the highest-ranking factor. One reason behind this concern is the recognition that middle-ranking officials could act on behalf of a PEP, circumventing AML/CFT controls. As a result, it’s entirely appropriate for firms to cover these less prominent public functions as customer risk factors as part of their enterprise-wide risk assessments, especially when exposed to high-risk jurisdictions.
Machine learning allows firms to monitor these positions continuously and be aware of real-time changes. ComplyAdvantage’s PEP screening solution also performs automatic updates every 30 days to ensure nothing is missed. This means that unannounced changes are discovered immediately. In case of significant changes, such as an upset election, firms can have new and updated PEP data coverage in a matter of hours after the results have been confirmed.
When it comes to PEP coverage, in particular, speed is vital. If businesses move too slowly, they may accidentally onboard a client that is too high risk or, conversely, continue applying overly stringent standards to a customer when they are no longer required.
Analyze negative news at scale with our robust screening software.
Find out moreOriginally published 14 May 2020, updated 22 January 2025
Disclaimer: This is for general information only. The information presented does not constitute legal advice. ComplyAdvantage accepts no responsibility for any information contained herein and disclaims and excludes any liability in respect of the contents or for action taken based on this information.
Copyright © 2025 IVXS UK Limited (trading as ComplyAdvantage).