

 En vedette
En vedette
La seule méthode à la fois puissante et efficace pour collecter des données est le recours à l’apprentissage automatique. La recherche de mots-clés uniquement par des humains est inefficace. Nous avons déjà abordé ce sujet en détail ici mais d’autres raisons confirment toute l’importance de l’apprentissage automatique pour la collecte de données.
Collecte de données
La collecte de données sur la couverture médiatique négative, les sanctions, les PPE et les RCA n’est pas une tâche facile et peut être encore plus difficile si elle est effectuée par des humains. Un humain ne peut travailler qu’un nombre limité d’heures par jour, a des aprioris sur ce qui est pertinent ou pas et est impacté par des événements d’envergure mondiale dont le fait d’être soudainement contraint de travailler à distance (ou dans certains cas, de ne pas pouvoir travailler à distance en raison de mesures de sécurité ou d’autres contraintes techniques).
Allier conformité et télétravail n’a pas été sans difficulté pour certains secteurs de l’économie. En raison de diverses préoccupations, certains spécialistes des données ont dû être mis au chômage technique, ce qui a eu un impact particulièrement important sur la collecte de données. Pour certains outils alimentés par les humains pour construire leurs données, on a constaté une augmentation de 200 % des faux positifs lorsque les fournisseurs n’ont pas pu s’appuyer sur l’apprentissage automatique.
L’apprentissage automatique est un moyen éprouvé de collecter efficacement les données et d’assurer la continuité des activités en temps de crise.
Filtrage par mots-clés uniquement
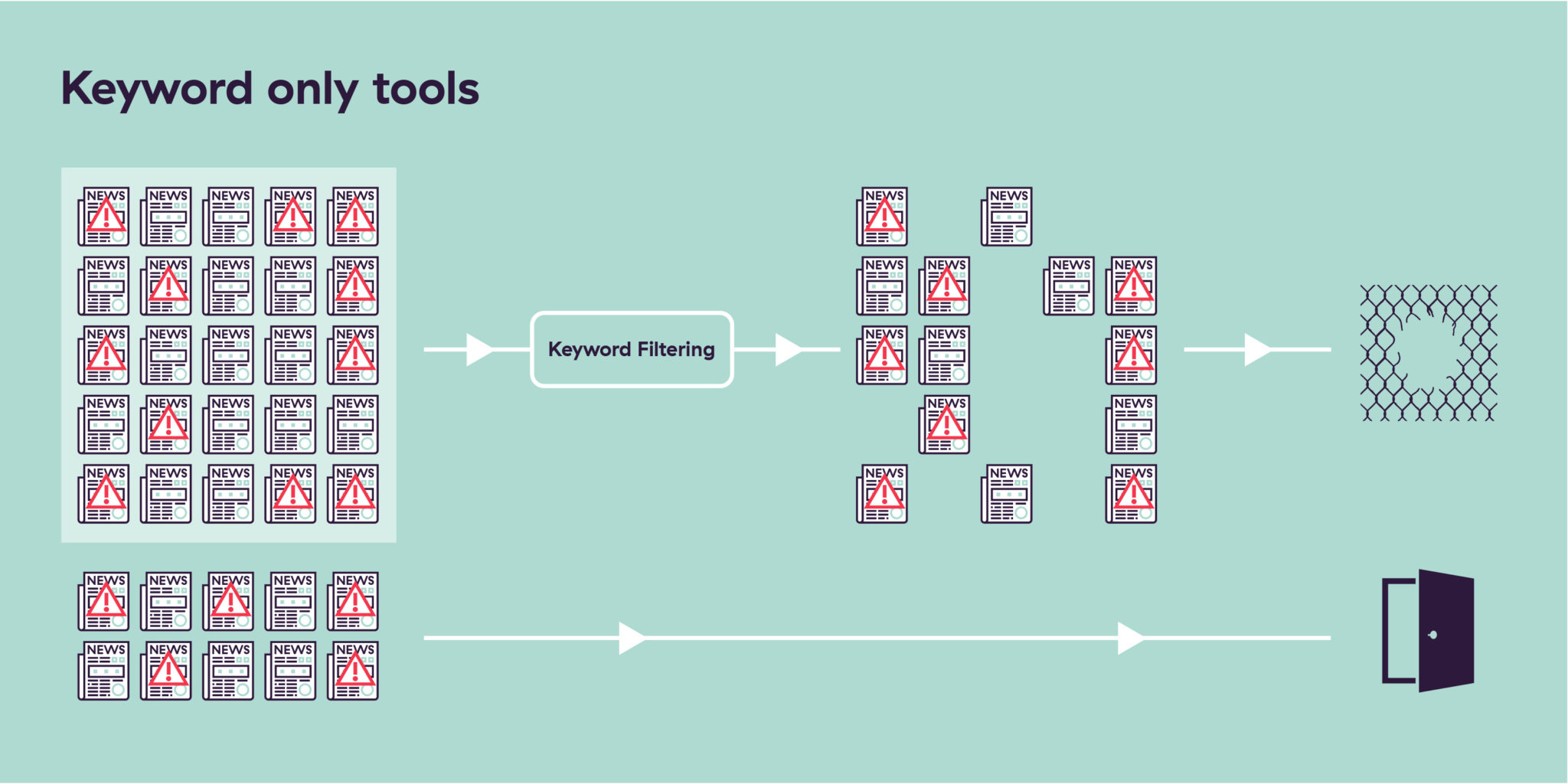
Il peut être difficile d’imaginer pourquoi les mots-clés sont inefficaces en soi. Lorsque vous intégrez des clients, vous devez être capables de vous référer à une base d’informations médiatiques négatives qui ne comporte ni erreurs ni lacunes grossières.
L’utilisation du filtrage par mots-clés entraîne l’analyse d’un nombre restreint de sources médiatiques sous peine que cette méthode soit complètement submergée par les résultats. Toutes les informations médiatiques négatives issues de ces sources sélectionnées n’incluront pas les mots-clés associés aux risques que recherchent les équipes de conformité et elles passeront donc à travers les mailles du filet.
Une fois cet ensemble limité de sources filtré au moyen de mots-clés, certains résultats liés à la couverture médiatique négative dont vous disposerez contiendront des informations médiatiques vraiment négatives et d’autres non. En tant qu’équipe en charge de la conformité, c’est un peu comme si une clôture grillagée entourait votre entreprise, la seule solution pour contenir de manière réaliste le volume de données à traiter, mais qui reste facile à pénétrer.
Concernant les informations médiatiques négatives qui ne figurent pas dans les sources sélectionnées, vous ne pourrez pas les détecter du tout. Vous ne saurez même pas qu’elles existent. Vous ouvrez ainsi la porte à des entités qui pourront faire partie de vos clients malgré vous.
Mots-clés et analystes
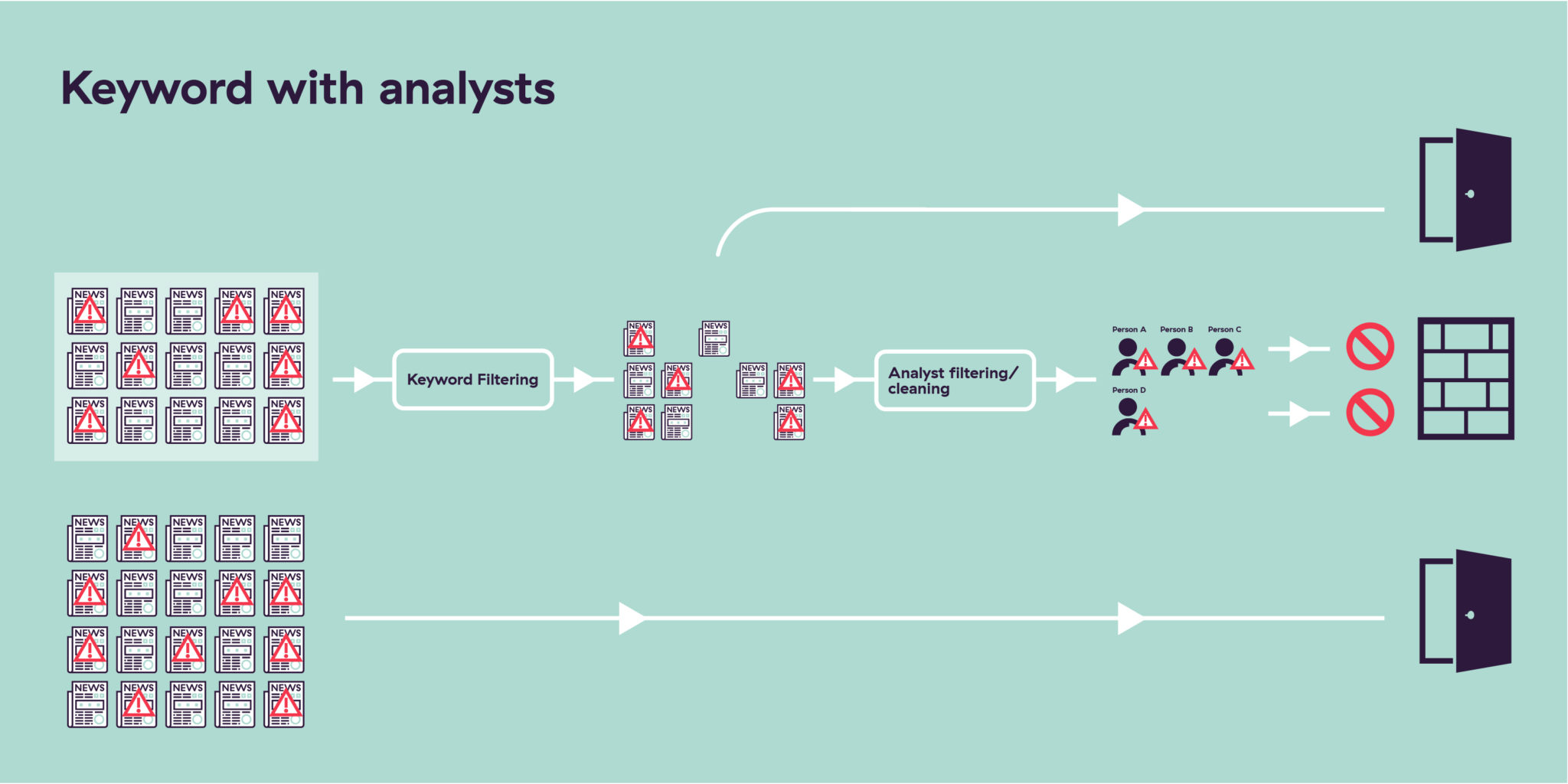
L’étape suivante, après le filtrage par mots-clés uniquement, consiste à ajouter des analystes à l’opération. Les analystes sont capables d’extraire les informations situées au niveau de la clôture grillagée et de filtrer ces données pour réduire les faux positifs, ce qui permet à votre équipe de conformité d’empêcher plus facilement des entités indésirables d’intégrer votre activité.
Malheureusement, cette approche a ses limites. En effet, humains avant tout, les analystes ne peuvent pas travailler sans fin tandis que leur subjectivité interfère avec le filtrage. C’est ainsi qu’ils pourront classer de manière inappropriée certains articles comme défavorables ou non ainsi que ceux considérés à tort comme non défavorables, si bien que des entités nuisibles pourront intégrer votre établissement financier sans plus de formalités.
Là encore, dans la mesure où le nombre de sources médiatiques analysées est limité, certaines sources ne feront tout simplement pas partie de l’équation. Et lorsque des analystes sont sollicités, même si la qualité des données est plus élevée que suite à un simple filtrage par mots-clés, moins d’articles seront passés en revue. Par conséquent, davantage d’entités sont omises et peuvent donc entrer dans votre entreprise par la petite porte.
Aussi, lorsque l’on tente de créer des profils pour ces entités, la tendance est à la création de doublons. Ceci est lié à la difficulté pour un humain de devoir analyser tous les profils existants dans la base de données afin de décider où ajouter des données. Bref, tout l’opposé d’un processus automatisé qui permet d’analyser facilement toutes les nouvelles données par rapport aux données existantes et donc sans les limites humaines de ce qui peut être traité en même temps.
Qui plus est, si, pour une quelconque raison, les analystes ne sont pas en mesure de travailler, l’efficacité du système s’effondre. Il s’ensuit une avalanche de faux positifs qui oblige les équipes de conformité à choisir entre ignorer un risque si elles font preuve de moins de rigueur ou compliquer la relation client en maintenant une certaine rigueur qui cependant rallonge sensiblement les délais d’intégration.
L’apprentissage automatique
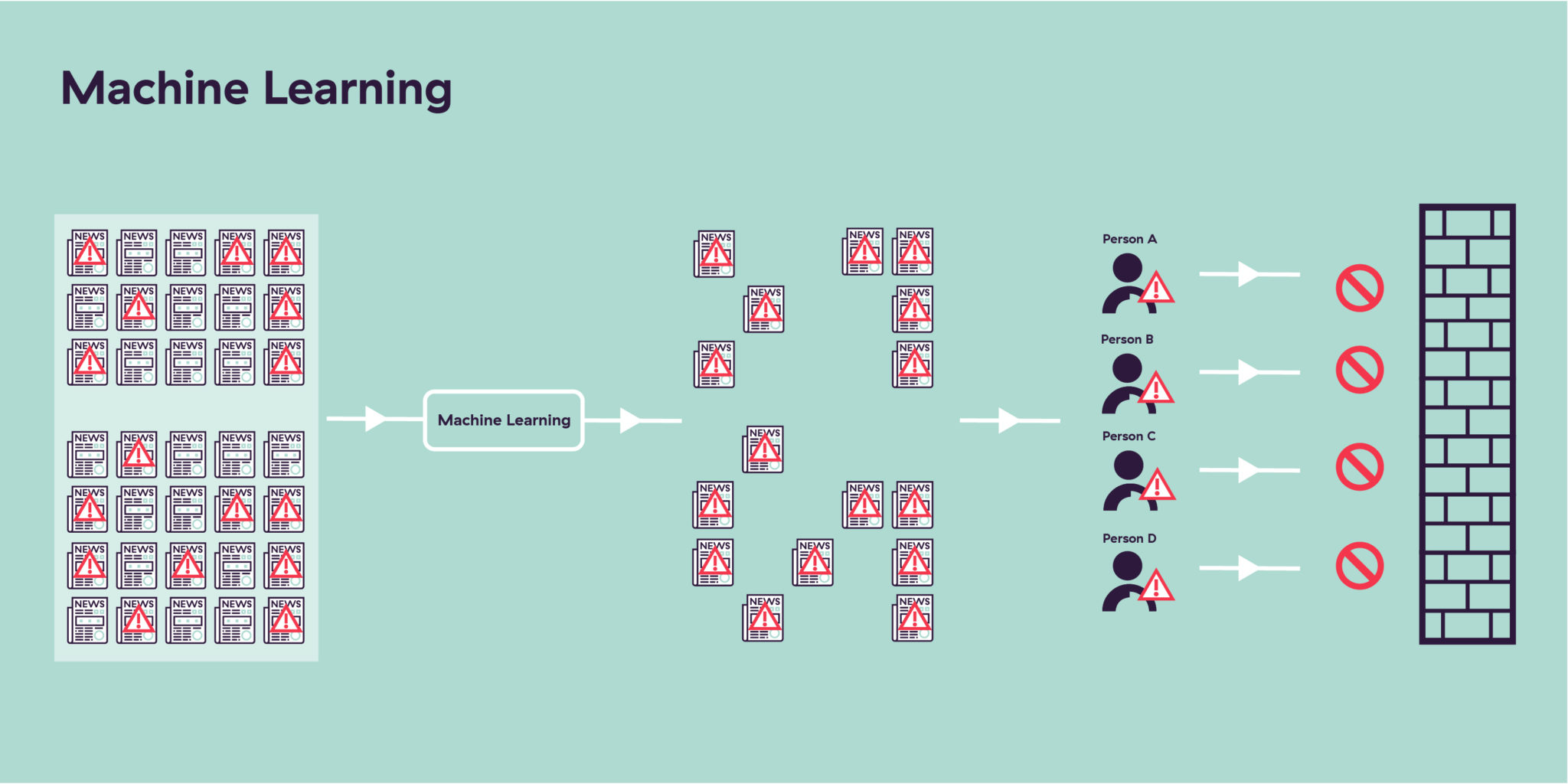
L’apprentissage automatique est clairement supérieur aux deux méthodes évoquées précédemment. Recourir à l’apprentissage automatique pour créer une base de données de médias défavorables et filtrer les entités n’oblige pas à limiter le nombre de sources à analyser en fonction du nombre de spécialistes des données disponibles. La seule limite est la réalité, à savoir les informations produites un jour spécifique par toutes les sources médiatiques appropriées. Inutile de sélectionner les médias à examiner. Tous sont analysables et analysés.
L’absence d’intervention humaine à ce stade permet aussi d’identifier en permanence et sans interruption les informations médiatiques négatives. Et ce quels que soient les événements qui peuvent bien se produire dans le monde.
Une fois les médias indésirables identifiés, l’apprentissage automatique, qui comprend le véritable contexte de l’article et pas seulement la présence de mots-clés, extrait les informations qu’il attribue ensuite à des profils correspondant à des entités bien réelles, le tout sans créer de doublons qui feraient perdre du temps aux analystes chargés de la conformité. Ensuite, lorsque ces entités tentent d’intégrer votre établissement, elles seront facilement identifiées et rejetées si besoin par l’équipe chargée de la conformité. Cela revient à élever un mur de briques autour de votre entreprise pour la protéger des éléments nuisibles.
Créer une base de données efficace sur les informations médiatiques négatives
Pour la collecte de données, il est nécessaire de s’appuyer sur l’apprentissage automatique, et ce pour différentes raisons. Tout d’abord, cette technologie permet de créer une base de données efficace sur les informations médiatiques négatives en examinant tous les médias disponibles. Elle fonctionne en continu et identifie les actualités négatives importantes et présente ces informations dans un format facilement accessible et utilisable avec notre système avancé de correspondance de noms et de filtrage des identifiants personnels.
L’apprentissage automatique fournit des profils d’entités rapidement utilisables pour décider d’intégrer ou non un client en fonction de l’appétit pour le risque de l’établissement financier concerné. Sans une solution basée sur l’apprentissage automatique, votre établissement ne pourra jamais identifier tous les clients pouvant représenter une menace pour vos obligations de conformité.
Mais d’autres raisons justifient aussi la collecte de données au moyen de l’apprentissage automatique. Cette technologie n’est pas seulement utile pour les informations médiatiques négatives. En effet, les informations sur les sanctions et les PPE évoluent sans cesse et les entreprises doivent s’assurer que leurs données restent à jour pour éviter de commettre une infraction ou de prendre des décisions trop risquées.
Données sur les sanctions
Les données sur les sanctions ne cessent d’évoluer. Il s’agit de données critiques pour un filtrage fonctionnant de manière binaire, à savoir que si une entité fait l’objet d’une sanction, l’entreprise ne peut pas traiter avec elle.
Cependant, malgré leur importance, aucune structure unifiée ne permet de transmettre ces données sur les sanctions aux entreprises qui doivent en être informées. Il faut savoir que les listes peuvent être modifiées sans préavis, que les désignations sont parfois attribuées de manière non structurée et que des modifications peuvent être apportées de manière tout aussi chaotique.
La technique de collecte de données basée sur l’apprentissage automatique que nous utilisons pour fédérer et classer les données relatives aux sanctions est plus efficace que toutes les formes de collecte de données manuelles. Mais lorsque nous lui associons un examen manuel, c’est-à-dire humain, les deux méthodes fonctionnent ensemble pour produire les mises à jour les plus précises et les plus complètes de l’ensemble des données sur les sanctions, et ce à une vitesse inédite.
Supervision manuelle – Fingerprints
Fingerprints est une fonctionnalité de l’apprentissage automatique que nous utilisons pour surveiller les sources de sanctions manuelles. Elle permet d’analyser la source toutes les deux heures et d’envoyer une notification pour déclencher une mise à jour chaque fois qu’un élément est modifié sur le site Web.
Examen manuel – Collecte des sanctions
Une fois que Fingerprints a déclenché la mise à jour, nous vérifions que seules les données correctes et au bon format sont intégrées à la production de l’ensemble de données sur les sanctions grâce à un outil d’examen manuel propriétaire.
Nous pouvons ainsi identifier, suivre, interroger et enregistrer l’activité liée à l’examen. Grâce à ce processus, nous maîtrisons parfaitement les données relatives aux sanctions afin d’identifier les éventuelles erreurs commises par les autorités de règlementation et d’éviter des retards dans la mise à jour manuelle des sources de sanctions.
En outre, nous pouvons empêcher et contrôler l’effacement d’entités sanctionnées et mettre à jour ponctuellement les données de tous les clients grâce à une supervision manuelle. Notre outil Fingerprints fonctionne aussi pour de nombreux sites Web et sources.
La collecte de données est définie par sa relation avec l’apprentissage automatique. L’intervention humaine est une étape nécessaire pour garantir sa qualité dans certains cas spécifiques, notamment pour les données sur les sanctions. Cependant, sans le concours de l’apprentissage automatique qui est capable de superviser et de réagir aux changements apportés aux données, aucune recherche humaine ne peut rivaliser avec la vitesse, l’étendue, la profondeur et la précision d’une collecte de données réalisée par l’apprentissage automatique.
Des PPE en constante évolution
Les personnes politiquement exposées (PPE) changent constamment de poste et de statut et introduisent de nouveaux acteurs sur le terrain. Il s’agit d’un aspect de la collecte de données qui évolue aussi vite que la politique et qui doit faire l’objet de mises à jour fréquentes.
Une couverture des PPE critiques est essentielle à toute entreprise proposant des services financiers. Grâce à l’apprentissage automatique, nous pouvons obtenir des informations sur les PPE de classe 1 dans 245 pays et juridictions dans les domaines du pouvoir exécutif, législatif et judiciaire, ainsi que sur les responsables de l’armée, de la police et de la sécurité civile et sur les membres des conseils d’administration des banques.
Mais c’est la rapidité des mises à jour produites qui confère toute sa valeur à l’apprentissage automatique.
En effet, l’apprentissage automatique nous permet de surveiller ces postes et fonctions en permanence et d’être informés de tout changement dès qu’ils se produisent. En outre, nous lançons une mise à jour automatique tous les 30 jours pour veiller à ne manquer aucune information. Ceci permet de découvrir immédiatement les changements non annoncés et, si ces derniers sont majeurs, notamment suite à des élections, nous disposerons d’une couverture des données des PPE actualisée quelques heures après la confirmation des résultats.
Concernant la couverture des PPE en particulier, la rapidité est primordiale. Si vous allez trop lentement, vous exploitez alors des données obsolètes qui vous feront intégrer accidentellement un client qui présente un risque trop élevé pour votre approche fondée sur le risque.
Il est essentiel d’utiliser des données à jour pour bien cerner votre client et savoir quand vous devez le soumettre à une vigilance accrue (EDD) sous peine de devoir passer des journées à éplucher de manière frénétique l’ensemble de ses transactions pour vous assurer qu’il n’y a pas eu d’activité suspecte ou bien de devoir déposer des déclarations d’activité suspecte rétroactives. Autant d’actions qui détournent vos responsables de la conformité du travail sur lequel ils doivent se concentrer.
La collecte de données opérée par votre fournisseur est vraiment importante car peu importe la qualité de vos processus internes si vous travaillez sur des données erronées… Vous prendrez dans tous les cas un mauvais départ et vous ne serez jamais en mesure de vous conformer efficacement aux obligations réglementaires.
Publié initialement 06 juillet 2020, mis à jour 20 décembre 2023
Contenus associés
En vedette
Avertissement : Ce document est destiné à des informations générales uniquement. Les informations présentées ne constituent pas un avis juridique. ComplyAdvantage n'accepte aucune responsabilité pour les informations contenues dans le présent document et décline et exclut toute responsabilité quant au contenu ou aux mesures prises sur la base de ces informations.
Copyright © 2025 IVXS UK Limited (commercialisant sous le nom de ComplyAdvantage)