


Il est très facile d’utiliser des mots-clés pour filtrer la presse négative mais les résultats obtenus ne sont pas forcément de qualité.
Les médias défavorables — aussi connus sous les appellations « presse négative » ou « couverture médiatique négative » (et parfois associés aux « personnes d’intérêt spécial ») — préoccupent de plus en plus les établissements financiers. Pouvoir prévenir la criminalité financière en s’appuyant sur des informations pertinentes provenant de milliers de publications produites par des centaines de milliers de journalistes et de chercheurs à travers le monde, est désormais perçu comme un complément indispensable aux approches actuelles en matière de gestion de la conformité et des risques. Toutes les principales autorités de surveillance et de régulation (GAFI, FCA, FinCEN, Wolfsberg, etc.) recommandent, et souvent exigent, de filtrer la couverture médiatique négative dont les clients et autres tiers peuvent faire l’objet. Les principaux établissements financiers vont généralement au-delà de ces recommandations pour anticiper les exigences des régulateurs mais aussi protéger leur marque sur un marché ultra concurrentiel.
Le défi pour ces établissements consiste à renforcer leurs défenses contre les risques liés aux médias défavorables sans pour autant compromettre la performance de leur entreprise ni la compétitivité de leurs produits. Les fournisseurs de données sur les risques ont cherché à relever ce défi de plusieurs manières. À ce jour, leur principale technologie consiste à filtrer la presse négative à partir de mots-clés. Le problème, c’est que cette méthode ne donne pas forcément de bons résultats.
L’origine des mots-clés
En effet, les mots-clés créent des failles dans vos défenses qui engendrent de gros problèmes de performances. Au départ, c’est via un processus de recherche manuelle qu’étaient créés les profils de « couverture médiatique négative » ou de « personne d’intérêt spécial ». Une imposante équipe d’analystes passait la presse au peigne fin et s’intéressait à toute personne présentant un risque LCB-FT significatif. Une fois l’existence éventuelle d’une occurrence antérieure vérifiée, l’information était consignée dans la base de données des risques. Et s’il était impossible de savoir s’il s’agissait de la même personne que le profil précédemment créé, le principe de précaution était appliqué (en créant alors un profil redondant).
Cela conduisait à une base de données petite, mais de relativement haute qualité – présentant néanmoins plusieurs problèmes majeurs :
- Ne pouvant ajouter qu’un nombre limité de profils, les analystes devaient s’en tenir à quelques publications de référence pour s’assurer de « tout » couvrir. Toutefois, ces publications de référence portent en général sur les grands sujets d’actualité et n’abordent pas l’actualité locale critique dans laquelle le client d’une banque pourrait davantage être mentionné.
- Parce qu’ils sont des êtres humains, les analystes interprètent l’actualité médiatique avec leurs propres biais et vision personnelle, au risque de passer peut-être à côté de certaines choses. Après tout, ce travail est plutôt fastidieux et ingrat, à savoir passer des articles de presse au peigne fin et ajouter des noms à une base de données, huit heures par jour. Et inutile d’espérer que les analystes les plus expérimentés s’attèlent à ce genre de tâche. N’espérez pas non plus qu’un analyste maîtrise les dizaines de langues nécessaires pour comprendre la presse dans les principaux pays à risque.
Aujourd’hui encore, beaucoup de bases de données sont créées de cette façon et disponibles auprès de fournisseurs de données réputés notoirement répertoriés. Mais les grosses lacunes dans leur couverture n’offrent pas une défense adaptée aux établissements qui cherchent vraiment à identifier les risques qui émergent de la presse négative en termes de LCB-FT et que des tiers peuvent leur poser.
Cette situation et l’essor des moteurs de recherche ont permis d’adopter une approche apparemment plus avancée et évolutive : celle des mots-clés pour filtrer la presse négative.
Les mots-clés dans le filtrage des médias défavorables
« Quels mots-clés utilisez-vous ? » est l’une des questions qui revient le plus souvent dans les discussions avec nos clients et prospects. Il est parfaitement logique de la poser dès lors qu’un fournisseur utilise des mots-clés pour filtrer la presse négative dans le but d’identifier les entités à risque.
Le filtrage de la presse négative par mots-clés est supposé à juste titre opérer comme suit :
- Vous recherchez votre client, John Smith, et le mot « fraude ».
- Vous obtenez des articles de presse contenant des séquences du type : « John Smith a été jugé coupable de fraude ».
Indépendamment de savoir si le John Smith en question est bien le vôtre, votre requête a globalement abouti. Un homonyme de votre client a été cité dans une phrase traitant du risque LCB-FT qui vous préoccupe.
Problème 1 : Présence d’entités sans couverture médiatique négative
Mais vous pouvez aussi obtenir le résultat suivant :
“Michael Jones a été jugé coupable de fraude, déclare le procureur John Smith.”
Vous avez obtenu un résultat, mais de toute évidence ce John Smith n’est pas l’auteur de la fraude et ce résultat n’est donc pas pertinent. En réalité, la plupart des résultats vont être des versions où la plupart des personnes citées dans l’article seront, selon le cas : la victime, un représentant de la justice, un témoin, un journaliste, etc.
Problème 2 : Différentes versions de mots-clés à risque
Et que dire de :
“Les procureurs estiment que John Smith a fait preuve d’un comportement frauduleux.”
Dans ce cas, le mot à risque était « frauduleux », mais la recherche portait sur « fraude », si bien qu’au lieu d’obtenir trop d’éléments parasites, vous êtes peut-être passé à côté d’un risque important. Sauf si vous incluez également certains mots-clés pour filtrer la presse négative tels que « fraude », « fraudes », « frauder », « frauduleux », « fraudé », « frauduleusement », etc.
Mais si vous incluez des dérivés particuliers du mot « fraude », pourquoi en rester là ? Pourquoi ne pas ajouter : « tromperie », « trompé », « arnaque », « arnaquer », « escroc », « escroquerie », « escroquer », « canular », « article truqué », etc. ? La liste est longue et les combinaisons sont quasiment infinies. Sans compter que certains mots sont moins utiles que d’autres pour identifier le risque. Au point qu’à un moment donné, vous allez devoir vous renseigner pour savoir si tel ou tel mot doit être inclus ou non pour tenter de faire la part des choses entre le risque de passer à côté d’une information importante et le volume d’éléments parasites que vous devez traiter.
Par ailleurs, si vous utilisez Google, vos recherches sont limitées à 32 mots…
Problème 3 : Des mots-clés à risque avec des sens différents
Prenons la phrase :
“John Smith l’a massacré dimanche. Il a tiré à sept reprises et marqué trois buts. Sa victime, le gardien de but Michael Jones, a clairement été blessé dans sa fierté.”
En tant que lecteur humain, nous comprenons immédiatement qu’il s’agit de sport, malgré les mots « massacré », « tiré », « victime » « blessé ». Cet exemple est simpliste mais le problème est classique car presque tous les mots-clés peuvent prendre différents sens selon le contexte. Au final, cette approche manque de précision. Pensez par exemple aux mots « blanchir », « accusé » ou même « arrêter ».
Problème 4 : Aucun mot-clé à risque dans une phrase clairement négative
Prenons un autre exemple :
“John Smith (47 ans) a été impliqué dans une affaire où Patience Chiwasa et des dizaines investisseurs avec elle ont perdu l’essentiel de leur épargne retraite.”
Que remarquez-vous ? Cette phrase ne contient absolument aucun mot-clé de filtrage de la presse négative. « Impliqué » est peut-être le mot le plus fort, mais son utilisation est souvent si banale dans d’autres contextes qu’il ne serait pas très prédictif. Malgré l’absence de mot-clé évoquant un risque, nous comprenons parfaitement en tant que lecteurs humains qu’un certain risque est associé à John Smith. Si nous comptons sur des mots-clés pour nous éclairer, nous ne comprendrons jamais de quoi il s’agit.
Problème 5 : Autres langues
Voyons enfin :
“John Smith was found guilty of fraud”
Il s’agit d’une version anglaise de notre premier exemple (« John Smith a été jugé coupable de fraude »). Pensez aux problèmes de base en français et voyez ce qui vous attend en les multipliant par le nombre d’autres langues qui vous intéressent, avec en prime toutes les subtilités idiomatiques à prendre en compte.
Traitement des résultats des mots-clés dans le filtrage de la couverture médiatique négative
Partons de l’hypothèse irréaliste que les résultats obtenus en utilisant des mots-clés sont bons (en faisant abstraction de tous les problèmes ci-dessus). Nous nous retrouvons avec une liste d’articles qui mentionnent un individu appelé John Smith qui fait l’objet d’une couverture médiatique négative. Et maintenant ?
Vous devez étudier tous ces résultats pour établir s’ils concernent ou pas le seul John Smith qui vous intéresse. Même s’il s’agit bien de lui (et pas des centaines d’homonymes qui feraient l’objet de médias défavorables ou de sociétés John Smith), vous devez vous assurer que vous avez consulté les articles les plus pertinents et que vous avez une vue globale des entités. À bien des égards, c’est à ce stade que commence le gros du travail.
En reprenant la question « quels mots-clés utilisez-vous (pour filtrer la presse négative) ? », la réponse peut être simple. Mais cette réponse occulte quantité de complications. À vrai dire, ce n’est pas la bonne question à poser. Il faudrait plutôt demander « Comment allez-vous détecter le risque global relatif à mon activité en faisant en sorte de réduire au minimum les informations parasites ? ».
Une alternative facilitée par l’apprentissage automatique
D’une certaine façon, les problèmes que pose l’emploi de mots-clés pour filtrer la presse négative peuvent être solutionnés par une approche humaine de l’analyse. Mais seulement à petite échelle. Que diriez-vous de pouvoir disposer de cohortes autrement plus nombreuses d’analystes travaillant 24 h sur 24, prenant des décisions cohérentes et impartiales, lisant la presse dans des dizaines de langues différentes et capables de se mettre à niveau constamment et immédiatement ?
Heureusement, cette perspective ne relève pas de l’utopie. En effet, depuis 2012, le domaine de l’apprentissage automatique (ou machine learning) a explosé grâce à une puissance de calcul toujours plus grande et à plusieurs techniques nouvelles. L’association de la technologie et du traitement automatique du langage naturel (TALN) a également fait irruption dans nos vies, notamment avec l’arrivée rapide de Siri, Alexa, Google Translate et d’autres outils devenus si compétents.
Chez ComplyAdvantage, c’est depuis notre création il y a 10 ans que nous utilisons cette technologie de filtrage pour produire des données LCB-FT à la fois volumineuses et de grande qualité. Le défi consistant à créer une base de données sur la couverture médiatique négative peut être parfaitement relevé par l’apprentissage profond et le TALN. Nous franchissons ainsi la barrière des mots-clés pour comprendre le véritable contexte dans la langue écrite.
Reprenons quelques exemples énoncés plus haut en les envisageant sous l’angle de l’apprentissage automatique. Les copies d’écran ci-dessous proviennent de « Mention Checker », un outil de diagnostic interne que nous utilisons en phase de développement. Nous voyons ce que le système a lu et compris, mais c’est quelques étapes avant que nous consolidions l’information et les identifiants dans un profil d’entité utilisé par nos clients.

Cas simples
Celui-ci est presque trop facile, une simple déclaration de l’entité et du crime commis, sans plus d’information.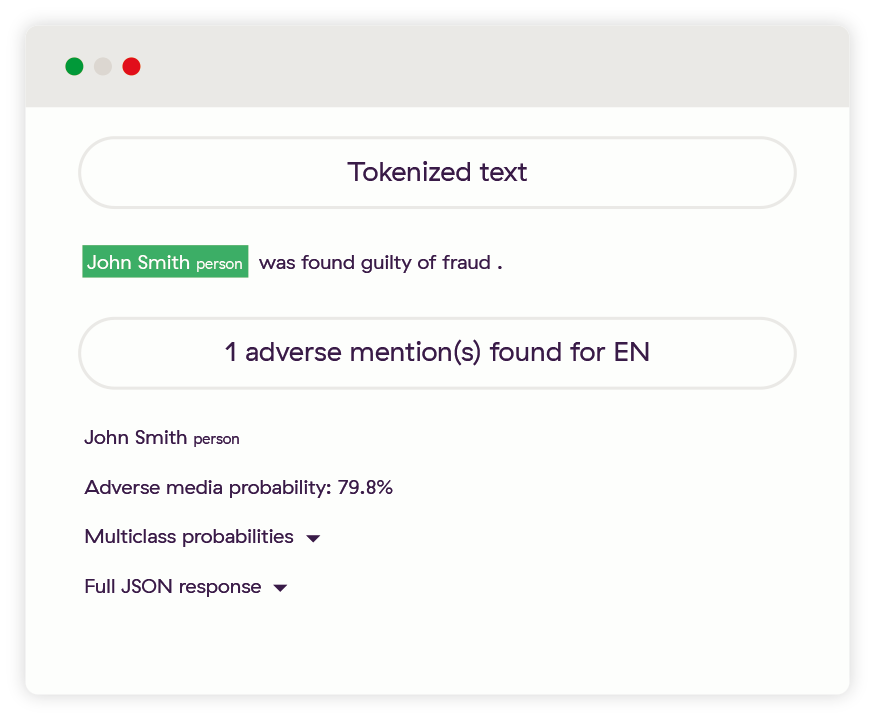
Amélioration 1 : Personne avec une couverture médiatique non négative dans les médias
Ici, il a été clairement établi que l’entité John Smith fait l’objet d’une couverture médiatique non négative, contrairement à l’entité Michael Jones.
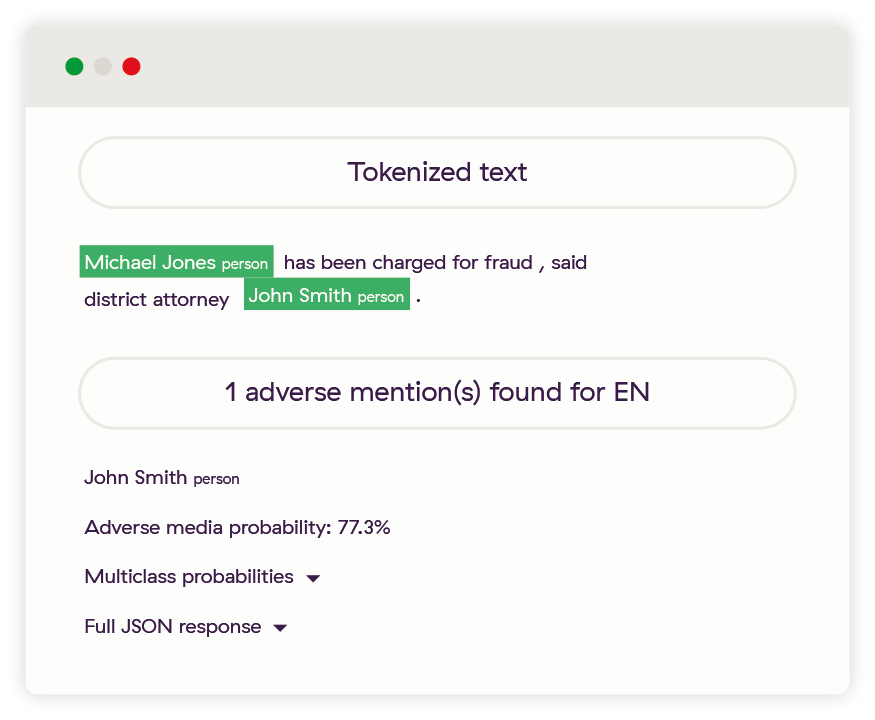
Amélioration 2 : Versions différentes des mots-clés à risque
Ici, le système a constaté que John Smith fait l’objet d’une couverture médiatique négative, malgré la présence de l’un des nombreux dérivés de la racine « fraude », qui est un mot-clé évoquant un risque.

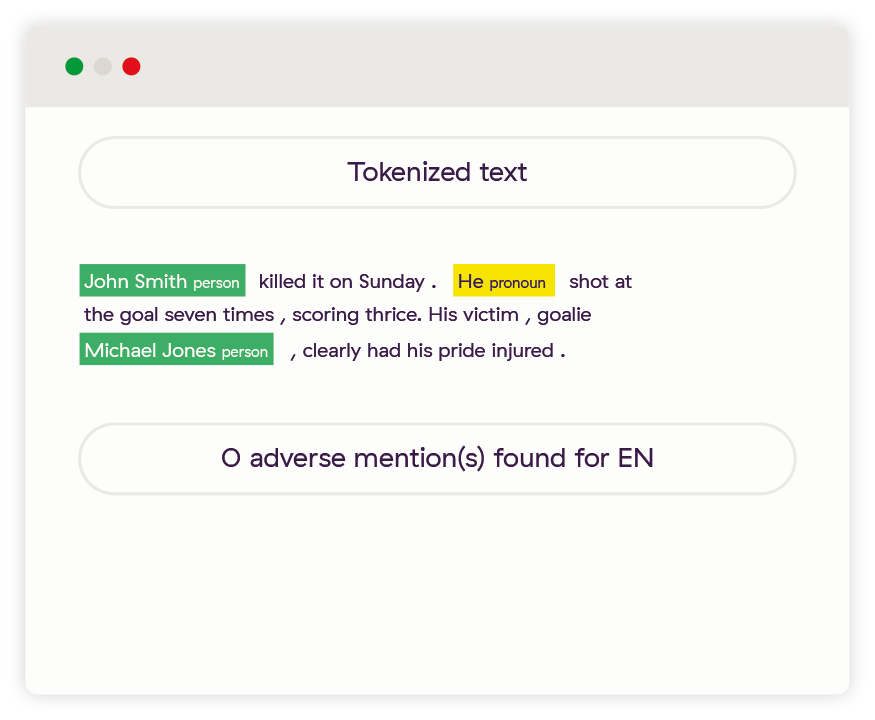
Amélioration 3 : Mots-clés à risque avec différentes significations
Bien que ces deux phrases comportent plusieurs mots évoquant le risque, il a été établi qu’aucune des entités ne fait l’objet d’une couverture médiatique négative.
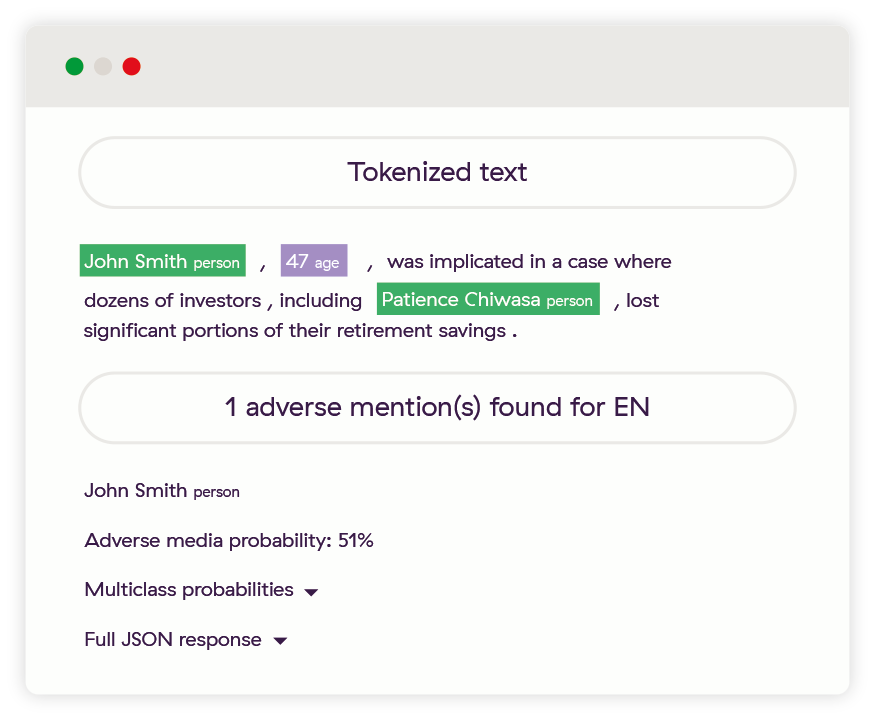
Amélioration 4 : Pas de mot-clé à risque dans les médias
Cet exemple montre la véritable puissance d’un système fondé sur l’apprentissage profond tel que le nôtre. Non seulement il est établi que John Smith fait l’objet d’une couverture médiatique négative d’après cet article de presse, mais nous avons aussi identifié facilement Patience Chiwasa (un patronyme traditionnellement difficile à analyser) et avons compris que cette personne ne fait pas l’objet d’une couverture médiatique négative. De plus, nous avons identifié un âge pour l’entité John Smith que nous utilisons pour calculer son année de naissance. Cela fait partie du profil que nous pourrions créer pour permettre aux établissements utilisateurs de filtrer facilement les informations non pertinentes d’après ce qu’ils savent de leurs propres clients.
.
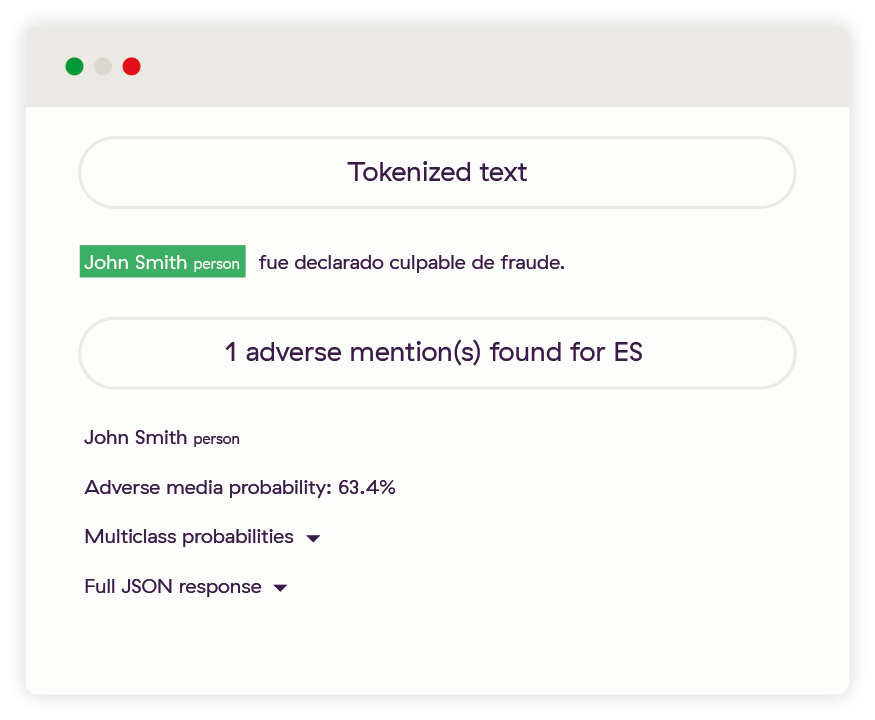
Amélioration 5 : Autres langues
Dans ce dernier exemple, il est facilement établi que John Smith fait l’objet d’une couverture négative dans la presse espagnole. Ce serait également le cas en portugais, en français, en allemand, en italien, en néerlandais, en russe, en arabe, en chinois ou encore en japonais.
Comment procédons-nous ?
Il faudrait plusieurs autres pages pour expliquer en détail la complexité de notre mode opératoire, mais penchons-nous sur certains composants qui sont au cœur de notre approche différente des mots-clés dans le filtrage de la presse négative.
Réseaux neuronaux profonds et imbrications de mots
Pour expliquer le fonctionnement de notre système, nous utilisons en interne la diapositive suivante. Elle foisonne de concepts, mais tenez bon !
En haut, vous observez un exemple de phrase. Notre système de production analyse jusqu’à un milliard de phrases par jour. La phrase est décomposée en éléments constitutifs :
- Un sujet est une personne, physique ou morale, que nous étudions dans ce contexte. Dans cet exemple, il s’agit de « John Smith ».
- Nous remarquons qu’une autre personne, Patience Chiwasa, est citée dans cette même phrase. Nous lancerons une nouvelle itération de l’analyse dans laquelle Patience est considérée comme le sujet.

Ensuite, tous les mots-clés pour filtrer la presse négative sont convertis en un format compréhensible pour une machine et compatible avec toutes les langues. L’image ci-dessous est un exemple simplifié de ce qui se produit. Chaque mot est converti en un vecteur (colonne de chiffres) qui le définit selon un ensemble donné de propriétés. Vous constatez ici que seul « King » (« Roi ») recueille une bonne note sous « masculinity » (« masculinité »), alors que seule « woman » (« femme ») est faiblement notée sous « royalty » (« royauté »). La liste des attributs est très, très longue. En réalité, elle n’est pas définie plus clairement que ça, mais il s’agit d’un concept général.
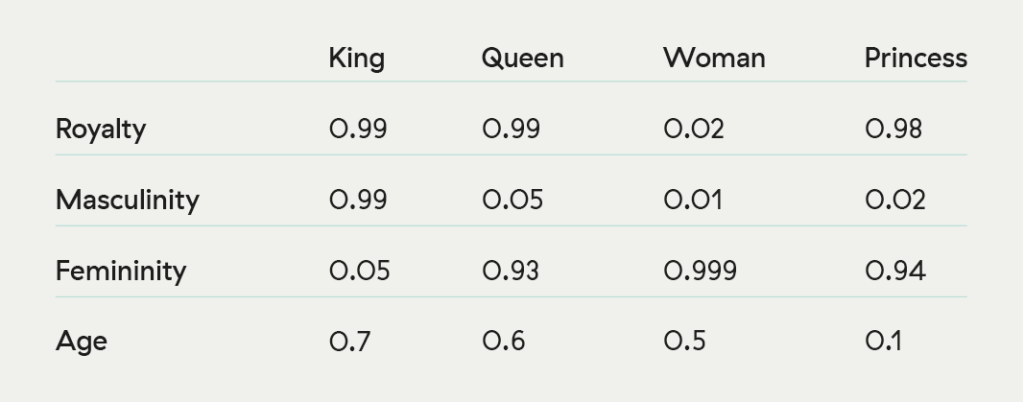
(Credit: Adrian Colyer – source)
Enfin, tous les mots-clés sont analysés via un réseau neuronal profond. L’intérêt d’un réseau neuronal est qu’il peut analyser chaque mot par rapport à tous les autres mots et tenir compte de l’ordre. Cela permet de :
- Comprendre comment, dans un texte donné, le contexte renvoie à des individus ou à des entités spécifiques.
- Comprendre comment un mot généralement négatif peut être utilisé dans un contexte non-négatif, ou inversement.
- Comprendre à quelle catégorie de presse négative peut appartenir quelque chose (par exemple « violence » ou « propriété » ou « lié à la fraude »).
Ce dernier point est crucial car la compréhension du contexte nous permet de déterminer si quelque chose est simplement négatif ou pas. Nous pouvons dire à quel type de presse négative se rattache quelque chose, ce qui permet à nos clients de gérer bien plus finement leur risque.
De nombreux exemples pour s’entraîner
Certains ingrédients sont indispensables à un bon apprentissage profond. Évidemment, il faut des ingénieurs talentueux mais également comprendre le problème. Cependant, un aspect souvent négligé est la nécessité de disposer d’exemples de bonne qualité pour entraîner des modèles. Un système d’apprentissage automatique a besoin de centaines de milliers, voire de millions, d’exemples pour fonctionner de manière optimale.
Nous avons fortement investi dans nos données d’entraînement, en coopération avec les meilleurs fournisseurs du domaine, en améliorant constamment nos modèles au fil des années. La qualité et la taille de nos mots-clés dans nos données d’entraînement au filtrage de la presse négative sont sans égales et s’améliorent sans cesse grâce aux retours de nos clients.
Conclusion : Les mots-clés dans le filtrage des médias défavorables
Les mots-clés étaient une étape intermédiaire pour réussir à faire évoluer le recours aux analystes et aux chercheurs recherchant manuellement des données de risque. Toutefois, cette méthode crée bien plus de problèmes qu’elle ne permet d’en résoudre.
Une approche fondée sur l’apprentissage automatique résout les problèmes créés à la fois par le chercheur et par les méthodes à base de mots-clés. Elle filtre correctement la presse négative (concernant la bonne personne physique/morale) à partir de la compréhension du contexte, et pas uniquement en fonction de la présence des mots-clés de filtrage de la presse négative. Elle peut le faire des milliards de fois par jour et ne se limite jamais à quelques publications seulement.
Notre technologie d’apprentissage automatique est au cœur de la manière dont nous avons créé la base de données de couverture médiatique négative la plus puissante au monde. Et cette technologie est loin d’avoir révélé tout son potentiel pour lutter contre la criminalité financière.
Filtrage automatisé des médias défavorables
Nous sommes à la pointe de la classification par apprentissage automatique, rassemblant toutes les informations et médias défavorables dont vous avez besoin dans des profils structurés et complets.
Commencez maintenant